Dify系列教程:本地部署与工作流搭建指南
Dify 是一个功能强大的开源 LLM 应用开发平台,其在工作流方面表现出色。本文将详细介绍如何在本地部署 Dify,并通过实际案例演示如何搭建工作流应用,帮助您快速掌握 Dify 的核心功能。
本地部署 Dify
为什么推荐 Dify,因为 Dify 在工作流方面表现出色,为此我将将推出一系列 Dify 的使用方法。今天是系列一。
Dify 在本地安装是基于本地 Docker,相信佬友们一定不陌生,Docker 的安装很简单,这里就不累述了。现在我们开始 Dify 的本地部署步骤:
一、获取 Dify 源代码有两种方法:
(一)使用 Git 命令
以管理员身份打开 Windows PowerShell,在 PowerShell 中,将你的文件夹设定为你要存放 Dify 源代码的地方
输入如下命令:
1 | |
(二)Github 项目中下载
点击 Code,选择 Download ZIP,下载后解压这个文件夹
二、在 Docker 中启动 Dify
先进入刚才下载的 Dify 目录下的 Docker 文件夹,找到 docker-compose.yaml 文件
在此文件夹下,输入 cmd 命令,启动终端,并输入如下命令:
docker compose up -d
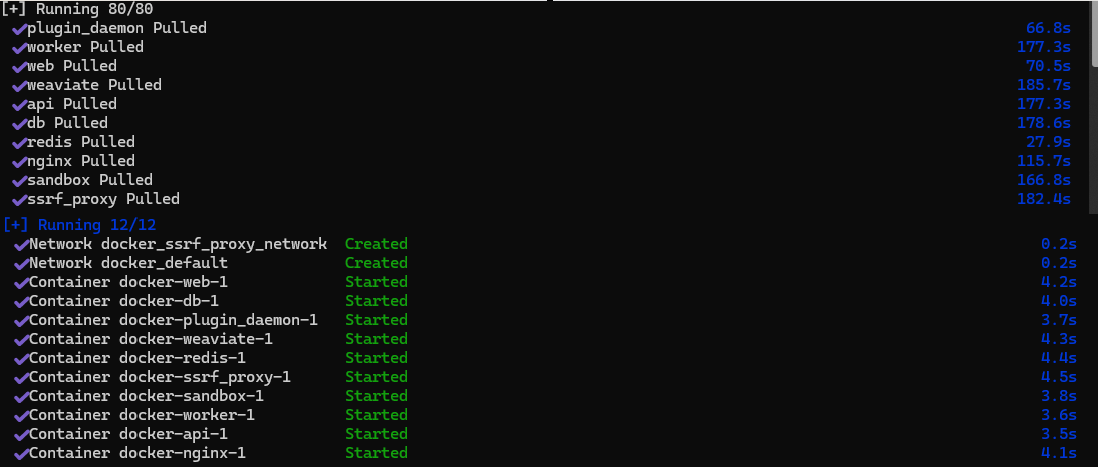
经过以上步骤,启动 Docker 就会发现 Docker 中多了一个名为 docker 的镜像,但是不像别的镜像一样,它没有端口号,实际上是正常的

三、运行 Dify
现在只需要在浏览器中输入 127.0.0.1,不需要任何端口号,就可以启动 Dify 了
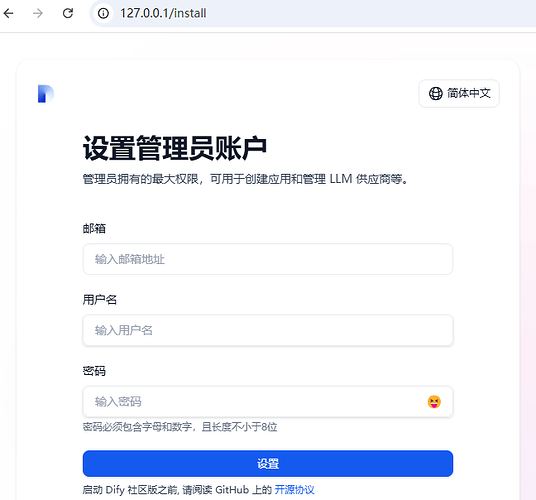
设置邮箱,用户名及密码后,就可以登录看到 DIfy 的全貌了
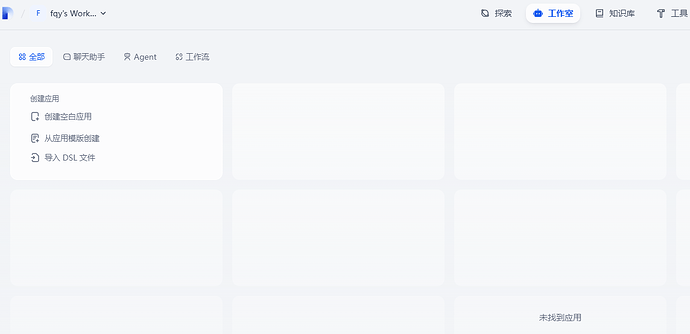
安装完 Dify,实际上并没有任何 AI 模型,实际上 Dify 就是一个 WebUI 而已。
配置模型
Dify 配置模型
1、Dify 部署好了,第一件事就是要为它配置模型,点击右上角用户名下拉菜单,点击 设置
2、点击 模型供应商,在这里就能看到许多已经可供安装的模型插件
3、为了演示,我就安装一个 Ollama 模型,鼠标移到模型上,直接点击 安装
4、会弹出窗口,继续点击 安装
5、安装好,在模型列表处就会出现 待配置 式样
6、点击右下角添加模型,会弹出如下窗口,添加已下载的 Ollama 模型名称,基础 URL
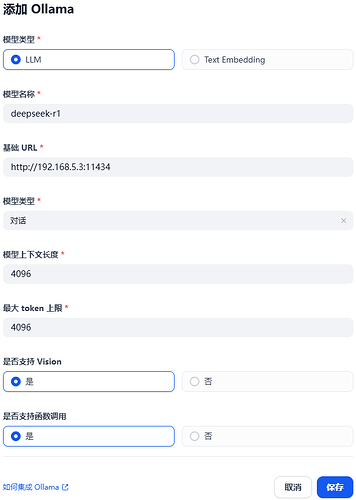
7、按照此方法添加了多个 Ollama 的模型
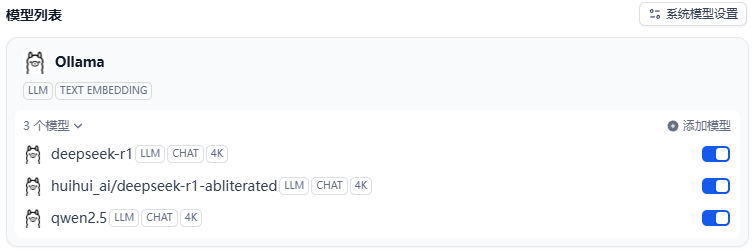
通过以上步骤,Dify 就已经配置好了模型,当然佬友们可以添加不同的模型,比如 Deepseek、硅基流动、Gemini 等等模型,只有填入对应的 API KEY 和 API 地址就可以了。
创建应用
本来想直接分享搭建 Dify 本地知识库的,但是一个创建新应用就够长了,就单独分享出来。
我先分享我搭建好的工作室中的一些应用,有辅助我做翻译工作的,有辅助我调试楼控软件的,有进行商业应用的,还有工作流等。
为了演示,我就搭建一个全新应用 —- 翻译助理。
1、点击上方的 工作室,点击左手边 创建空白应用

2、给应用一个 名称
3、点击名称后方的图标,可以自己上穿一个新图标
4、点击 创建, 刚才创建的 翻译助理 就已经创建好了
5、在 提示词 中可以使用 Dify 内置的一些提示词,但是过于简单。我建议填写 一段科学提示词,可以让它更好的为我们工作

6、有了上面这些工作,在右上方指定模型,这里我选择了 Claude-3.5-haiku,右下方与机器人聊天输入框中,只要输入英文,不再需要给它任何其他提示,它就直接进行翻译了,而且从翻译的内容看,专业,且输出了也是按照我们要求的 Markdown 格式。

选择了 Ollama 的 Deepseek-r1,看到它思考的过程,翻译也同样专业出色。
创建本地知识库
要创建本地知识库,第一件事就是要添加 Embendding 模型。之所以添加这样的模型,因为它可以把复杂、高维的数据(比如文本、图像等内容)转换成低维向量。
在构建知识库的过程中,我们将各类文档、研究报告、技术手册等资料,通过向量化处理后存储于专门的向量库中。当我们提出问题时,系统可以快速在这个库中,精准定位相关知识。这不仅是数据的存储,更是一种智能的知识映射和快速检索方式。
以上是重要知识点的铺垫,现在开始正文内容,创建本地知识库。
1、添加 Embendding 模型,点击右上角用户名,点击 设置,点选 模型供应商
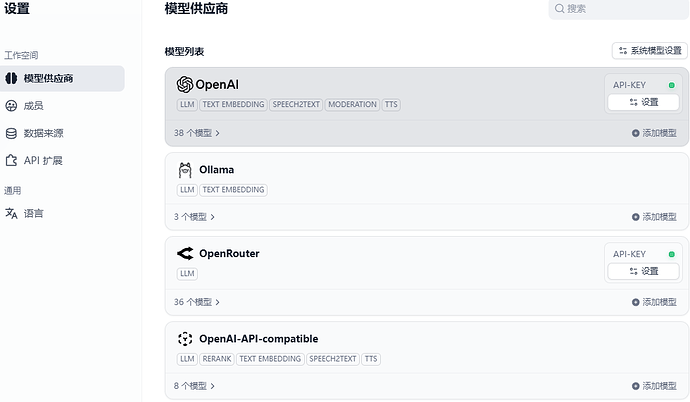
2、这里还是用 Ollam 模型进行演示,点击 添加模型, 将模型类型设定为 Text Embedding ,填入模型名称及基础 URL ,点击 保存
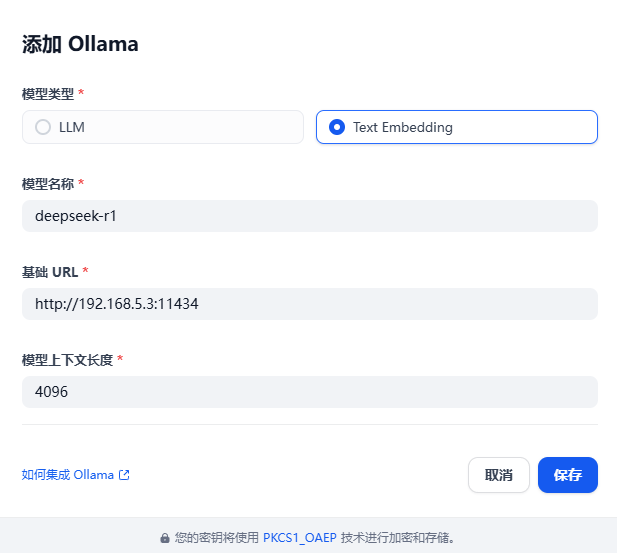
3、在 Ollama 中就看到刚添加的 Embendding 模型了
4、现在点击上方的 知识库,并且点击下方左边的 创建知识库
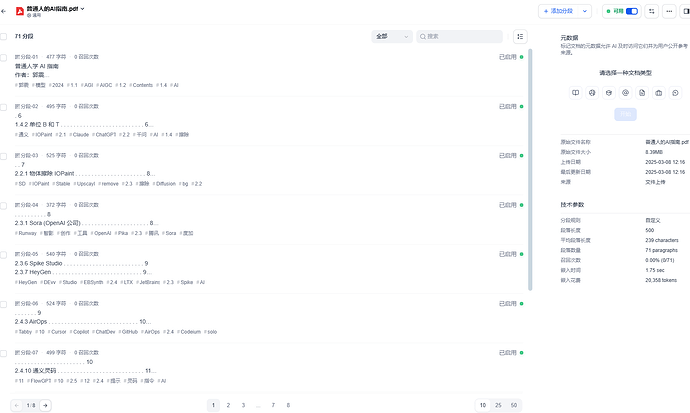
5、在下方界面中,选择 导入已有文本 ,上传文本文件,文件类型可以是 txt、markdown、pdf、html、docx 等等格式,这里我就上传一本《普通人的 AI 指南》的 PDF。
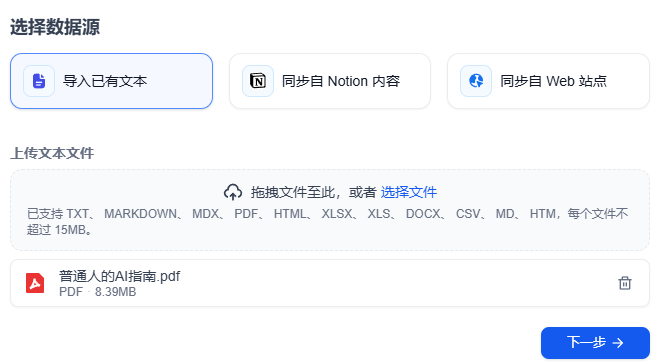
6、下一步就是选择合适的模型,并配置相关参数。左上方的 分段设置 中参数保持默认即可。索引方式用高质量。
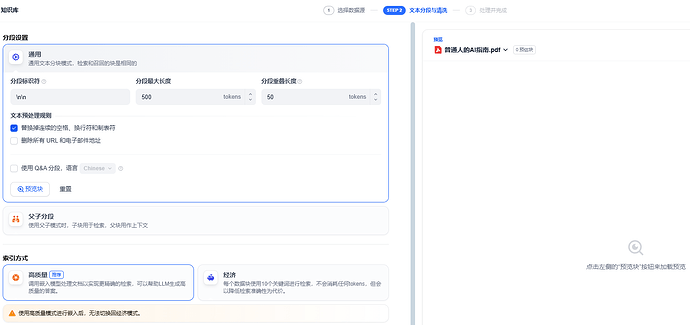
Embedding 模型,我们就用上面创建 deepseek-r1。检索参数无需调整,保持默认,直接点击最下方的保存处理即可
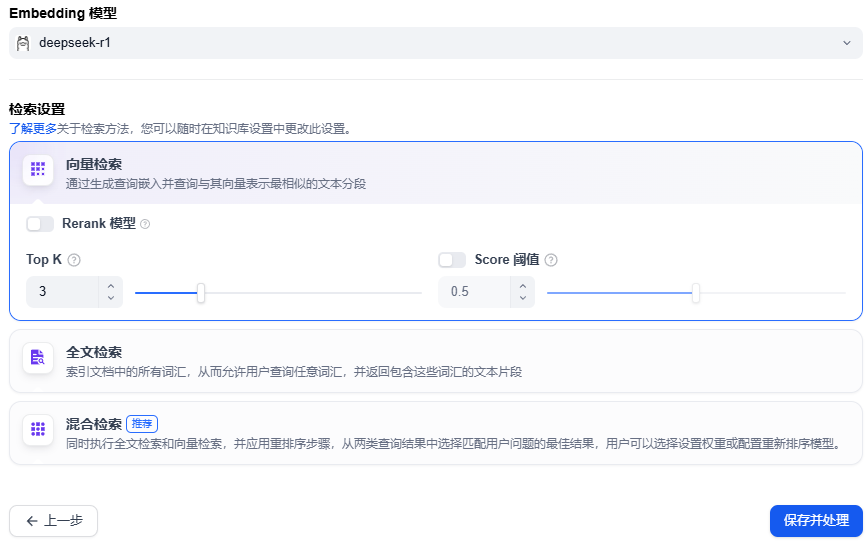
7、现在就需要耐心等待,dify 会自动对上传的文档进行解析和向量化处理。这个过程需要的时长不等,取决于文档的大小和复杂程度。
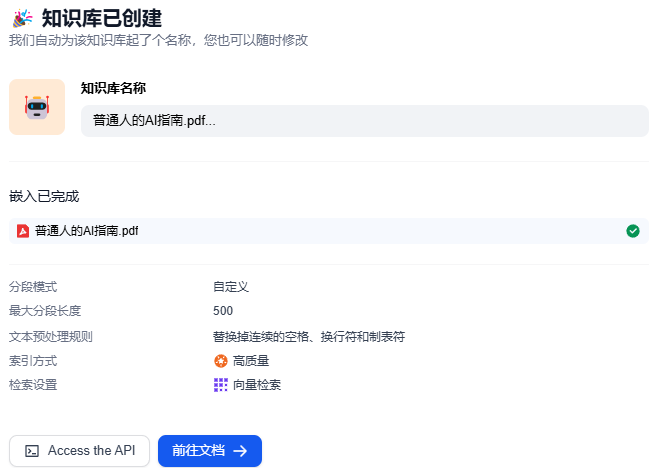
8、当显示嵌入完成,点击 前往文档,点击上传的文档,就可以看到此文档的分段情况

9、现在返回到工作室窗口,自建一个聊天窗口,就可以导入知识库作为上下文。
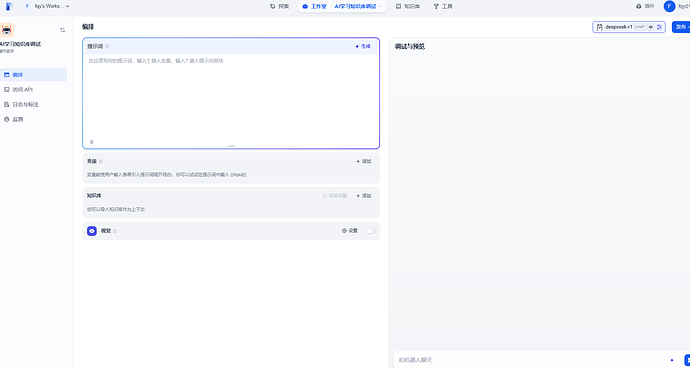
10、点击 添加,选择刚才已经创建好的知识库。
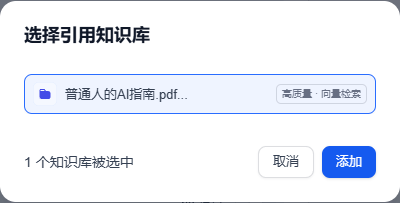
11、就可以看到我们刚创建的知识库已经添加成功了

现在就可以在聊天窗口中提问,看它是如何回答的,是否调用的是我们添加的知识库了。
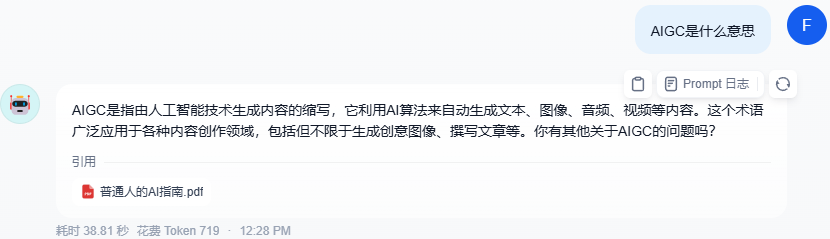
 image832×334 20.5 KB
image832×334 20.5 KB

以上的问答可以看出,在聊天窗口中我们提问后,AI 回答都是从我们创建的知识库中寻找答案,而不再是它自我进行内容组织了。
在实际应用中,关于知识库的搭建,我自己上传了 10 本专业书籍,与 AI 的对话中,它帮助我的专业软件改进了节点控制方法,非常有帮助。
知识库的搭建可以在各方面帮助到我们。
比如学生可以把日常的书本、笔记、资料等上传到知识库中,就拥有了私有的学习知识库,可以大大提高学习效率,在复习阶段是最有用的。如果写论文,只要让你的知识库充满参考资料和相关论文,让 AI 辅助你查询相关资料,提取各种文档,这得省去你多少查资料的时间啊!
公司则是可以将内部的档案、刊物、资料、文档等上传创建公司专有的知识库,以后再查找相关内容时,就不用人工翻阅,系统就会快速检索给出正确的内容,大大提高工作效率。有些公司因为保密机制,甚至可以在整个知识库搭建完成后,在内网中运行,既事半功倍、又达到保密机制的要求。
搭建工作流
初次接触 Dify 工作流的佬友,可能会被其繁多的节点和复杂的配置选项所困扰,感到无从下手。但无需焦虑,只要掌握其底层逻辑,这些节点和组合技巧便会变得清晰易懂。Dify 工作流的精髓,可以归结为一句话:** 数据的流动与转化是一切的核心。**

目前 Dify 工作流分成两种类型:
第一种:对话工作流,它可以应用于技术支持、客户服务、交互问答、搜索内容等场景。适用于实时对话,要求快速响应和自然语言处理。
第二种:工作流,它可以应用于复杂的任务编排,允许用户自定义节点处理复杂流程。强调任务自动化以及提升效率。如数据分析、批量处理、多步骤完成等工作流场景,需要逻辑编排以及外部工具协同完成任务。
我们在系列四知识库的分享中,实际上已经与对话工作流有了初步的认识,因此此次的分享,我们就以工作流为例,与佬友们一起零基础搭建一个工作流。
我先大体讲一下这个工作流的前提,领导给了一个纽约时报的财经专栏网址,主要报道特朗普与美国现行经济政策的一些新闻。是纯英文网站。领导想看看这个网站的中文新闻要点。如果常规我们需要先找到新闻,然后英译汉,再找出新闻要点,再编辑成文。领导一定会嫌弃工作效率太慢。
现在我们只需要搭建一个工作流来就可以完成这个工作。我们要做的是先用网络爬虫爬取新闻,然后让模型完成英译汉工作,再由模型扮演一名编辑完成新闻要点的摘录。
现在我们开始完成这个工作流,如果感兴趣,可以一起动手做。
1、我们点击工作室,点击工作流,点击创建一个空白应用,我给它赋予了一个新闻稿翻译并编辑成文的工作流名称。
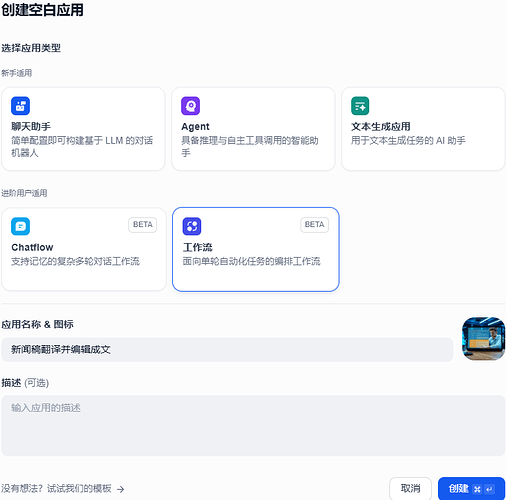
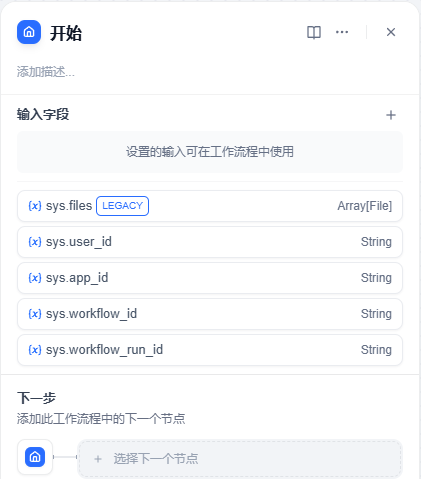
2、进入工作流界面,首先看到的是一个开始节点。右侧则是这个节点的参数配置页,这里的参数,我们暂时用不到,因此先留空。

3、点击开始后边的 + **号,我们点击工具 ,点击网页抓取,点选网页爬虫,这样操作后,就会发现在开始节点后有了网页爬虫**这个节点
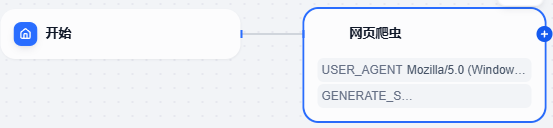
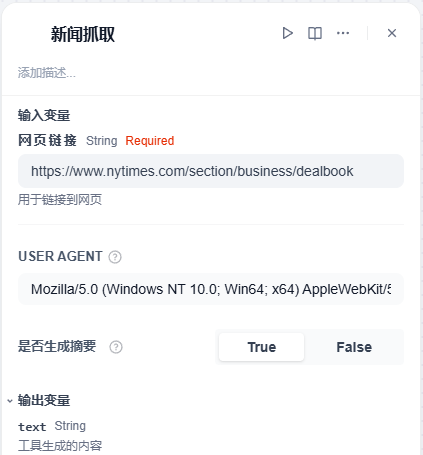
4、右侧的网页爬虫参数配置中,把这个节点名称修改成新闻抓取,并且将要抓取的文章网址粘贴到网页链接中,输出变量保持不变,但是后面的操作会用到 text 这个变量
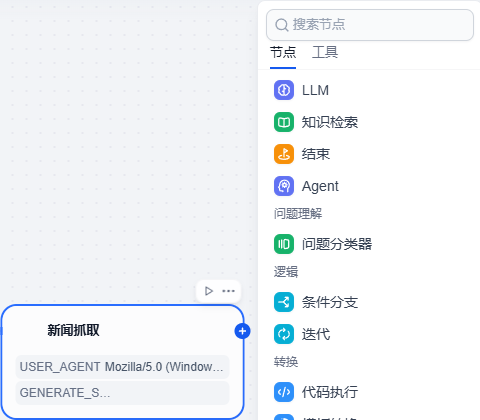
5、点击新闻抓取后的 + **号,在节点中选择 LLM**,就会看到这个节点了
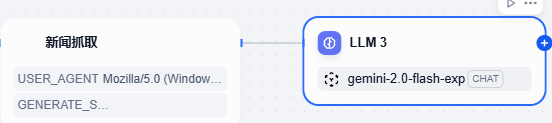
6、在 LLM 右侧的参数配置中,做如下修改,将 LLM 修改为英文翻译,选定了 gemini-2.0-flash-exp 作为模型(模型可以自选)。
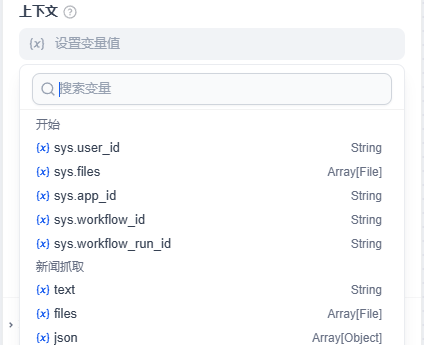
将上下文中选定新闻抓取中的 (x) text 变量

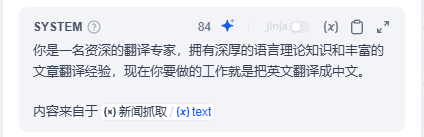
在系统提示词中,这样写
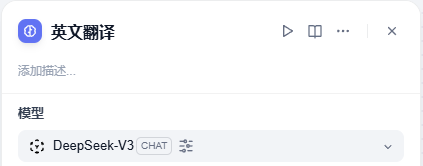
7、点击英文翻译后边的 + **号,在节点中还是选择 LLM**,就会看到这个节点

在右侧的参数配置中,将这个节点名称修改为新闻编辑,将 DeepSeek-V3 选定为这个节点的模型,因为它对中文的理解更好。
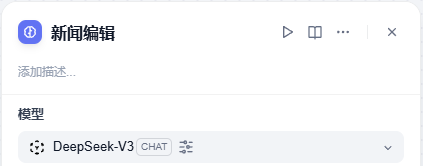
在上下文变量中则是选择,英文翻译 (x) text 作为上下文
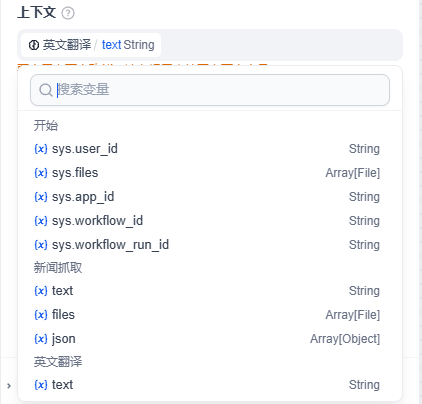
在系统提示词中,这样写
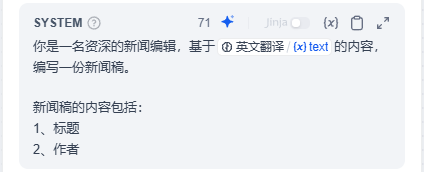
8、按照工作流的工作方式,这个流程需要给它添加一个结束节点,点击新闻编辑后面的 + 号,在节点中选择结束

在结束右边的参数栏中,名称修改为完稿,变量选择新闻编辑中的 (x) text 变量。
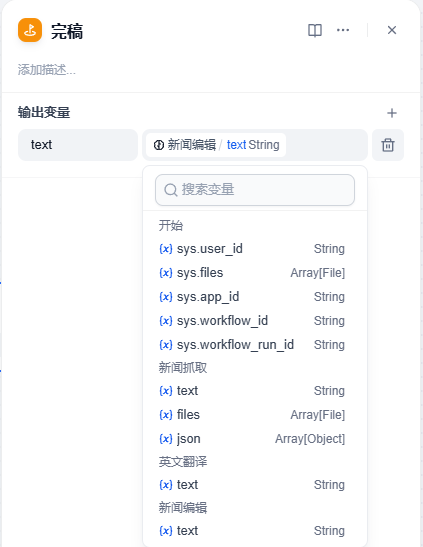
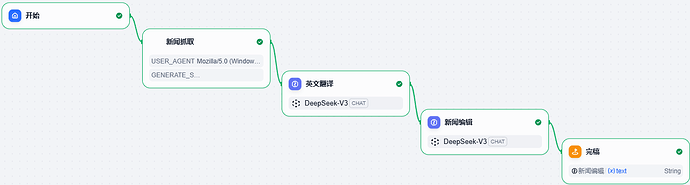
到这里这个工作流就算搭建完成了。为了让这个工作流更好看,我拖拽一下这个略显单调的一条线工作流。这样整个工作流的流程就清晰可见了。
[
让整个工作流工作有两种方式:
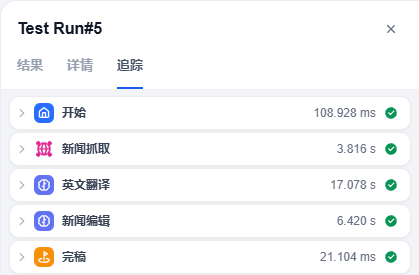
第一种是点击右上角的运行,这样做,可以亲眼看到工作流的工作流程,从哪个节点到哪个节点,包括所消耗的时间。
第二种方式,点击右上角的发布,再点击运行
会弹出一个对话框,点击运行
最终这个工作流完成了我们设定的流程,提供了最终的编辑文稿。

只需要几十秒钟,这个工作流就高效自动地完成了网页的爬取,翻译,编辑成稿的一系列流程。这次领导应该不会再说慢了吧。
以上就是 Dify 工作流的一个搭建过程。这里只是举了这么一个实例来展示这个工作流的搭建过程,实际上触类旁通,它还可以完成很多的工作流。
在实际工作中,我用它搭建了财务报表的自动筛选统计自动生成 PDF 报告、公司多种营销推广文案一键生成、多模型相互协作翻译大型文稿校对、公司内部档案资料的查询、以及软件关键节点的筛查及改进等工作流的搭建。
Dify 的灵活性和可扩展性使其能够应用于各种场景。无论是自动化流程、数据分析、客户服务,还是创意项目,都可以通过 Dify 的工作流实现。结合 AI、物联网、大数据等技术,Dify 工作流的应用可以进一步扩展,满足更多复杂的需求.